B300 Draws 1,400W Per GPU. Most Data Centers Aren't Ready.

NVIDIA's B300 GPU draws up to 1,400W per chip. That is double the H100, which shipped barely two years ago.
A single GB300 NVL72 rack, fully loaded with 72 of these GPUs, pulls 132 to 140 kW under normal operation. To put that number in perspective, the global average rack density in data centers sits at roughly 8 kW. So the B300 needs about 17 times the power of a typical rack. And according to Uptime Institute's 2024 survey, only about 1% of data center operators currently run racks above 100 kW.
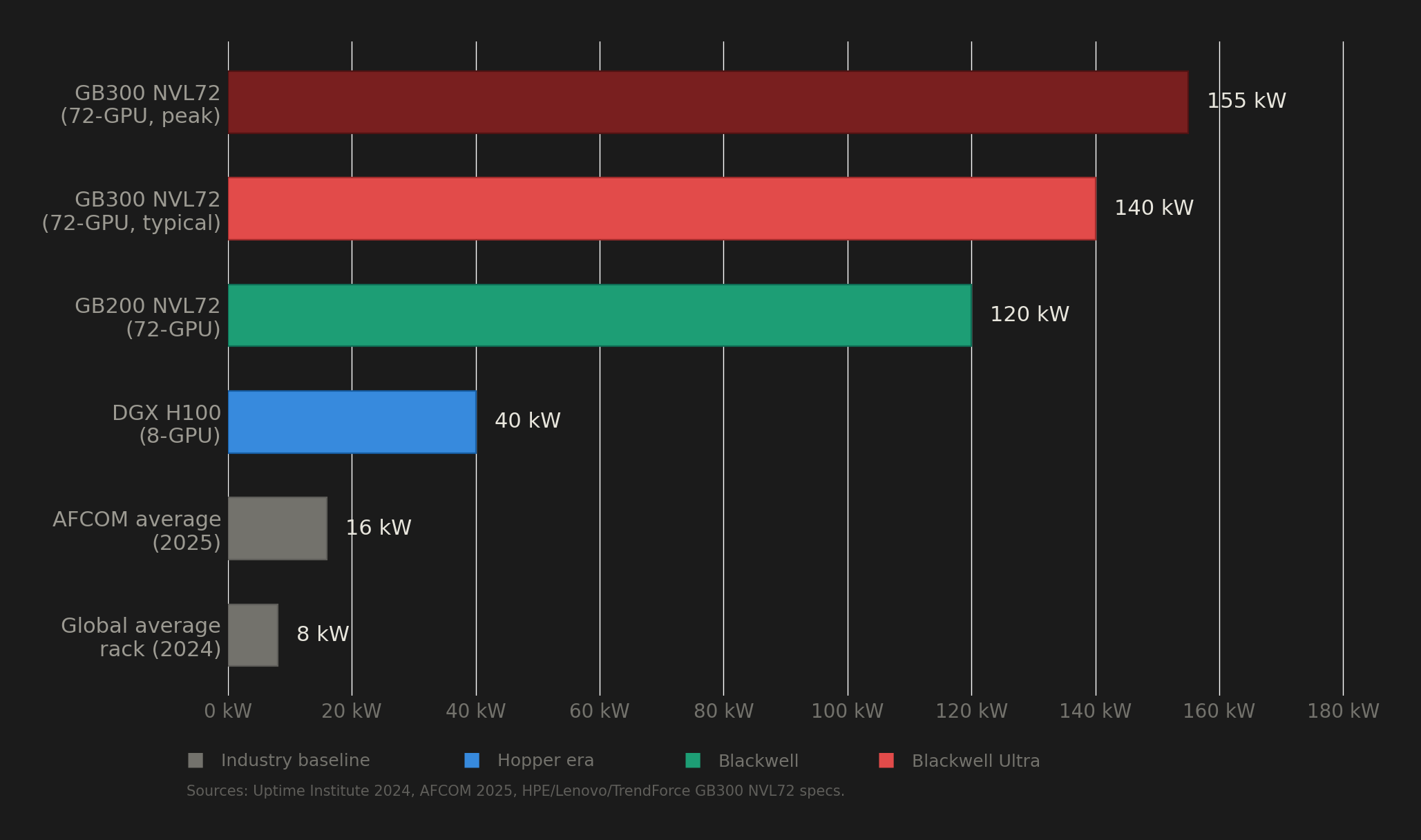
That gap between what the B300 demands and what the world's data center infrastructure can actually deliver is the story nobody is telling properly. Behind every cloud GPU instance running Blackwell Ultra is a facility that had to solve problems in power delivery, liquid cooling, and grid access that most buildings on earth are not equipped to handle.
This post breaks down the real infrastructure cost of running B300s, the deployment problems operators have already encountered, and why the electricity grid itself is becoming the binding constraint on AI compute scaling.