B300 Draws 1,400W Per GPU. Most Data Centers Aren't Ready.

NVIDIA's B300 GPU draws up to 1,400W per chip. That is double the H100, which shipped barely two years ago.
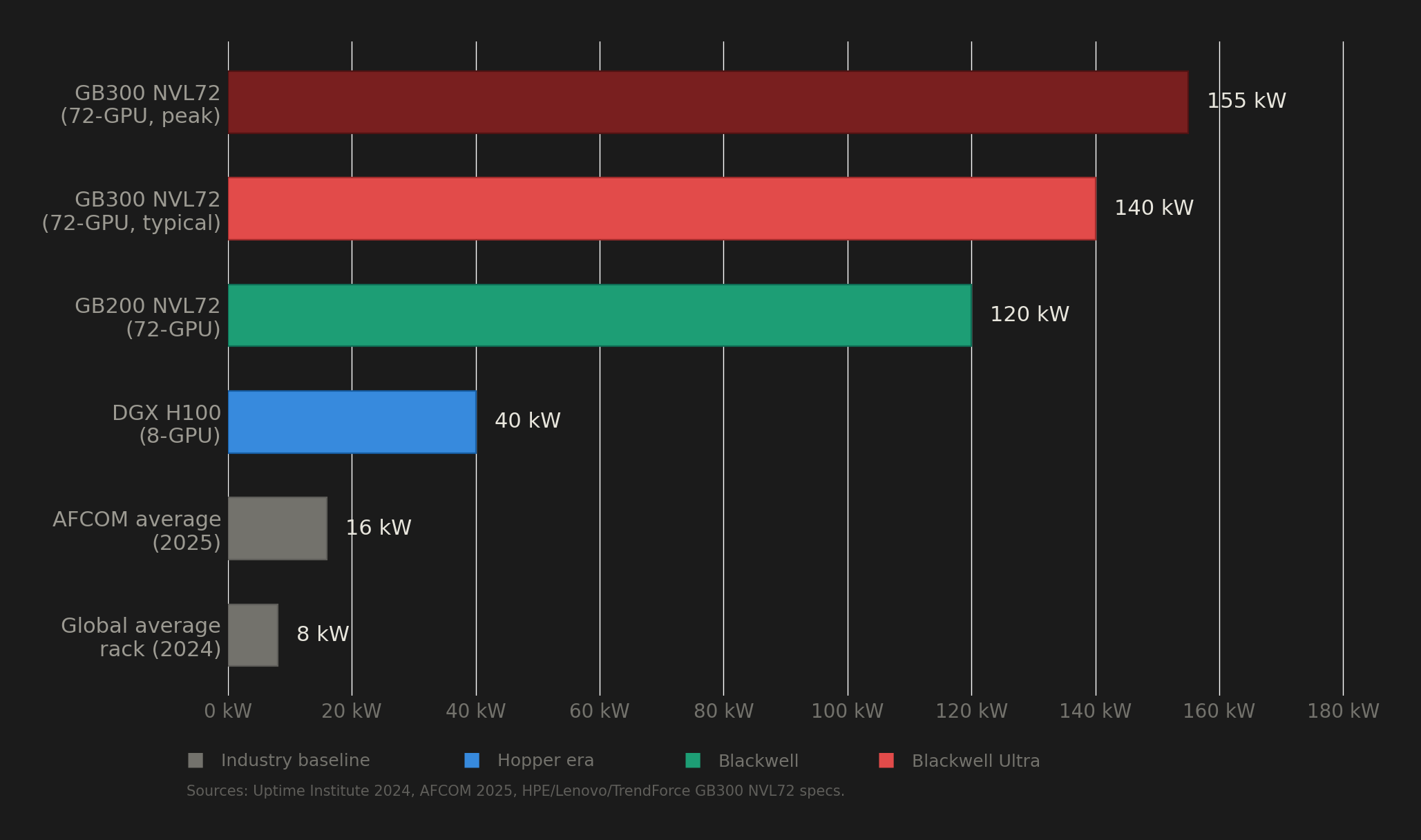
A single GB300 NVL72 rack, fully loaded with 72 of these GPUs, pulls 132 to 140 kW under normal operation. To put that number in perspective, the global average rack density in data centers sits at roughly 8 kW. So the B300 needs about 17 times the power of a typical rack. And according to Uptime Institute's 2024 survey, only about 1% of data center operators currently run racks above 100 kW.
That gap between what the B300 demands and what the world's data center infrastructure can actually deliver is the story nobody is telling properly. Behind every cloud GPU instance running Blackwell Ultra is a facility that had to solve problems in power delivery, liquid cooling, and grid access that most buildings on earth are not equipped to handle.
This post breaks down the real infrastructure cost of running B300s, the deployment problems operators have already encountered, and why the electricity grid itself is becoming the binding constraint on AI compute scaling.
The power trajectory from H100 to B300
The TDP of NVIDIA's data center GPUs has been climbing fast, but the B300 represents a step change rather than a gradual increase.
Here are the numbers from NVIDIA's published specifications:
| GPU | Architecture | Max TDP | Memory |
|---|---|---|---|
| H100 SXM | Hopper | 700W | 80 GB HBM3 |
| H200 SXM | Hopper | 700W | 141 GB HBM3e |
| B200 (in GB200 NVL72) | Blackwell | 1,200W | 192 GB HBM3e |
| B300 (in GB300 NVL72) | Blackwell Ultra | 1,400W | 279 GB HBM3e |
That 1,400W figure applies specifically to the GB300 NVL72 rack configuration, which is the liquid-cooled, 72-GPU, rack-scale system. In the HGX B300 (an 8-GPU air/liquid hybrid server), the B300 caps at 1,100W. This distinction matters because the system form factor determines the thermal envelope, and most coverage does not differentiate between the two.
The rack-level power math does not simply multiply 1,400W by 72 GPUs. The GB300 NVL72 uses power sloshing across its 18 compute trays (each containing 4 GPUs and 2 Grace CPUs), dynamically redistributing power between processors depending on workload phase. The result is a rack-level draw of 132 to 140 kW under typical load, with peaks reaching 155 kW. HPE, Lenovo, TrendForce, and Schneider Electric all report numbers within this range.
Inside the rack, a 50V DC busbar runs vertically through the chassis. Up to eight 1U power shelves, each containing six 5.5 kW PSUs at 94.5% efficiency, connect to 415V three-phase AC via 160A IEC 60309 connectors. At 120+ kW and 50V, the busbar carries over 2,500 amps. That is a lot of copper, and it is pushing conductor physics to the edge of what fits inside a standard rack footprint.
NVIDIA demonstrated an 800V DC sidecar PSU at GTC 2025, but that targets the Rubin platform expected in 2027. Current GB300 NVL72 deployments run on standard 400V three-phase AC or 48 to 54V DC distribution.
Liquid cooling is not optional
There is no air-cooled configuration for the GB300 NVL72. None. The system uses a hybrid cooling architecture where 90% of heat removal happens through direct-to-chip liquid cooling and 10% through supplemental air. Every GPU, CPU, NVSwitch, and ConnectX-8 NIC gets a cold plate with liquid flowing through it. Only auxiliary components like OSFP transceivers, storage drives, and M.2 modules rely on airflow.
This is a hard requirement, not a recommendation.
The system circulates a water-glycol coolant mix. Reference specifications from the GB200 NVL72 (the closest publicly available data) call for inlet temperatures of 20 to 25°C, flow rates around 80 liters per minute, and pressure drop below 1.5 bar. Lenovo's GB300 Product Guide confirms the system supports "warm water" operation, meaning it can run with water-side economizers supplying water below 45°C, which avoids energy-intensive mechanical chillers.
One detail that does not get enough attention: the GB300 introduced 252 pairs of quick-disconnect connectors per rack, up from 108 in the GB200. NVIDIA designed a new connector (NVUQD03) at one-third the size of its predecessor. Blind-mate manifolds let operators service individual compute trays without draining the entire coolant loop.
All of this adds up. A Morgan Stanley teardown analysis puts the cooling bill of materials for one GB300 NVL72 rack at approximately $49,860. The cooling hardware alone costs as much as a high-end car.
For organizations retrofitting existing air-cooled facilities, the numbers get worse. Converting to liquid cooling runs $2 to $3 million per MW of cooling capacity. For a 100+ kW rack deployment, that translates to roughly $200,000 to $300,000 per rack in infrastructure costs before a single GPU is powered on. Microsoft reportedly spent approximately $1 billion on liquid cooling retrofits across its data center fleet.
Interestingly, building a new liquid-cooled facility from scratch is actually cheaper than an air-cooled one: $8 to $12 million per MW versus $10 to $15 million per MW. Liquid cooling requires less physical space. The penalty falls entirely on organizations that already built air-cooled facilities and now need to convert them. That retrofit cost premium runs 40 to 80% higher than building for liquid from the start.
The grid cannot keep up
Power availability, not cooling technology, is becoming the binding constraint on AI infrastructure deployment.
PJM Interconnection operates the power grid across 13 eastern U.S. states, including Virginia's "Data Center Alley," which hosts the highest concentration of data centers on the planet. In its December 2025 capacity auction, PJM failed to procure enough generation capacity for the first time in its history. The shortfall was 6.6 GW. Capacity prices exploded from $28.92 per MW-day to $333.44 per MW-day. That is close to a tenfold increase.
This is not a temporary blip. AEP Ohio imposed a moratorium on new data center connections in 2023 after its queue exceeded 30,000 MW of requests. Dominion Energy in Northern Virginia has publicly acknowledged it cannot meet data center power demand, delaying projects by years. In Texas, ERCOT's large-load interconnection requests reached over 230 GW in 2025, nearly quadruple the prior year, with more than 70% coming from data center developers.
The IEA puts global data center electricity consumption at 415 TWh in 2024, roughly 1.5% of worldwide electricity. Under base-case projections, that doubles to 945 TWh by 2030, which is equivalent to Japan's entire national electricity consumption. Goldman Sachs forecasts data center power demand will grow 165 to 175% by 2030 compared to 2023 levels, with AI's share rising from 14% to 39% of total data center power.
Tech companies are responding by signing nuclear power deals at a pace that would have seemed absurd three years ago. Microsoft signed a 20-year agreement with Constellation Energy to restart Three Mile Island Unit 1, an 835 MW reactor, targeting 2028. Google signed the first-ever corporate SMR fleet deal with Kairos Power for up to 500 MW. Amazon is backing 5 GW of SMR projects through 2039. Meta issued an RFP for 1 to 4 GW of new nuclear generation. Oracle is planning a gigawatt-scale data center powered by three small modular reactors.
The local pushback is growing. Between March and June 2025 alone, $98 billion in data center projects were blocked or delayed by community opposition. Over 100 counties and cities have passed moratoria, zoning limits, or new environmental regulations since 2023.
Early deployments have not been smooth
The path from NVIDIA's keynote stage to production racks has been rough.
The Financial Times reported in May 2025 that GB200 NVL72 racks suffered from overheating, software bugs, chip-to-chip connectivity issues, and leaking liquid cooling systems. NVIDIA asked suppliers to change rack designs multiple times, altering cooling plate geometry and coolant flow rates. Each NVL72 rack contains over 2,000 cables for power, networking, and cooling. Deviations from specified bend radius cause bit errors that can reduce effective bandwidth by up to 40%.
Microsoft reportedly cut its GB200 orders by 40% in late 2024 due to production difficulties. SemiAnalysis noted as of early 2025 that no large-scale training runs had been completed on GB200 NVL72 and that even the most advanced operators at frontier labs were unable to carry out mega training runs on the platform.
Suppliers including Foxconn, Inventec, Dell, and Wistron eventually worked through the issues and began shipping at the end of Q1 2025. CoreWeave became the first cloud provider to offer GB200 NVL72 commercially (February 2025) and first to deploy GB300 NVL72 (July 2025).
For the GB300, NVIDIA made a notable trade-off: it reverted to the older "Bianca" chip board layout rather than the newer "Cordelia" design. The Bianca layout does not support individual GPU replacement. If one GPU fails in a compute tray, the entire tray needs service. NVIDIA deferred the more maintainable architecture to the Rubin generation. That is a real operational cost for anyone running these systems at scale.
For organizations deploying today, the infrastructure overhead on top of the hardware itself is substantial. A 1,000-GPU GB300 deployment approaches $200 million in total investment when including the 40 to 50% overhead for power and cooling infrastructure beyond the server hardware.
So what do you actually do with this information?
The B300 is a generational leap in compute. It is also a generational leap in infrastructure complexity. The silicon is not the hard part anymore. Power delivery and cooling are.
If you are an ML engineer or startup founder evaluating GPU infrastructure, the B300 forces you to think about your facility before you think about your model. Can your data center deliver 140 kW to a single rack? Does it have a liquid cooling loop rated for 80+ liters per minute? Can your utility provider actually connect you before 2028? If the answer to any of those is no, on-prem B300 is not a realistic path.
For most AI teams, the infrastructure burden of Blackwell Ultra makes cloud GPU access the practical choice. The power constraints, mandatory liquid cooling, multi-year utility interconnection queues, and $200,000+ per-rack retrofit costs are not problems that scale down to a 10-person startup. They are problems that exist at the facility level regardless of how many GPUs you need.
The most important GPU specification in 2026 is not FLOPS or memory bandwidth. It is whether the infrastructure behind the GPU can actually keep it running.
If your workloads run on H100s, H200s, or B200s, barrack.ai provides on-demand access to these GPUs with per-minute billing, zero egress fees, and no long-term contracts. No infrastructure headaches. Just compute.
FAQ
How much power does a single NVIDIA B300 GPU consume?
Up to 1,400W TDP in the GB300 NVL72 rack configuration (liquid-cooled). In the HGX B300 (8-GPU server), the cap is 1,100W. The specific number depends on the system form factor.
Can the B300 be air-cooled?
The HGX B300 (8-GPU server at 1,100W per GPU) can use a hybrid air/liquid cooling approach. The GB300 NVL72 (72-GPU rack at 1,400W per GPU) requires mandatory direct-to-chip liquid cooling. There is no fully air-cooled option for the NVL72.
How much power does a full GB300 NVL72 rack consume?
132 to 140 kW under typical operation, with peaks up to 155 kW. This is approximately 17 times the global average data center rack density of 8 kW.
What does it cost to cool a single GB300 NVL72 rack?
The cooling bill of materials per rack is approximately $49,860 according to a Morgan Stanley teardown. Ongoing electricity for cooling adds roughly 10% on top of the GPU power draw (at PUE 1.1 for liquid-cooled deployments).
Can existing data centers support B300 racks?
Most cannot. Only about 1% of data center operators worldwide currently run racks above 100 kW (Uptime Institute, 2024). The GB300 NVL72 at 132 to 155 kW requires liquid cooling infrastructure, high-amperage power distribution, and utility capacity that the vast majority of existing facilities lack.
What cooling infrastructure is required for the GB300 NVL72?
Direct-to-chip liquid cooling with water-glycol coolant, inlet temperatures of 20 to 25°C, flow rates around 80 liters per minute, pressure drop below 1.5 bar, and 252 pairs of quick-disconnect connectors per rack. Retrofitting an air-cooled facility for this runs $2 to $3 million per MW.
Is the B300 more energy-efficient than the H100?
Per FLOP, yes. NVIDIA claims 5x throughput per megawatt versus Hopper. But the absolute power draw per GPU is 2x higher (1,400W vs. 700W), and rack-level density is far greater. Efficiency gains at the chip level are being offset by deployment scale.
What deployment issues have been reported with Blackwell racks?
Overheating, liquid cooling leaks, inter-chip connectivity problems, software bugs, and cable management challenges (over 2,000 cables per rack). NVIDIA requested multiple rack redesigns from suppliers. Microsoft reportedly cut initial GB200 orders by 40% due to production difficulties. These issues have been substantially resolved as of Q1 2025, but they illustrate the operational complexity of this hardware.